
The Hook: Why “Skills” Sound Smarter Than They Are
The current discourse around AI “skills” is noisy for a simple reason: the word sounds like capability, progress, even a form of learning. That framing is convenient for demos and marketplaces. It is also misleading.
From a systems perspective, a skill is not intelligence. It is not a new reasoning engine. It is not proof that the model has learned a reusable capability in the way engineers usually mean learning. In practice, a skill is a structured way to constrain how a model receives instructions, how it decides the next step, and which tools it is allowed to call.
The useful mental model is more boring, but far more accurate:
$$ \text{Skill} = \text{standardized prompt} + \text{workflow logic} + \text{execution metadata} $$
That distinction matters. If you treat skills as packaged intelligence, you will buy the wrong abstractions. If you treat them as workflow artifacts layered on top of a probabilistic model, you can reason about failure modes before production teaches the lesson more expensively.
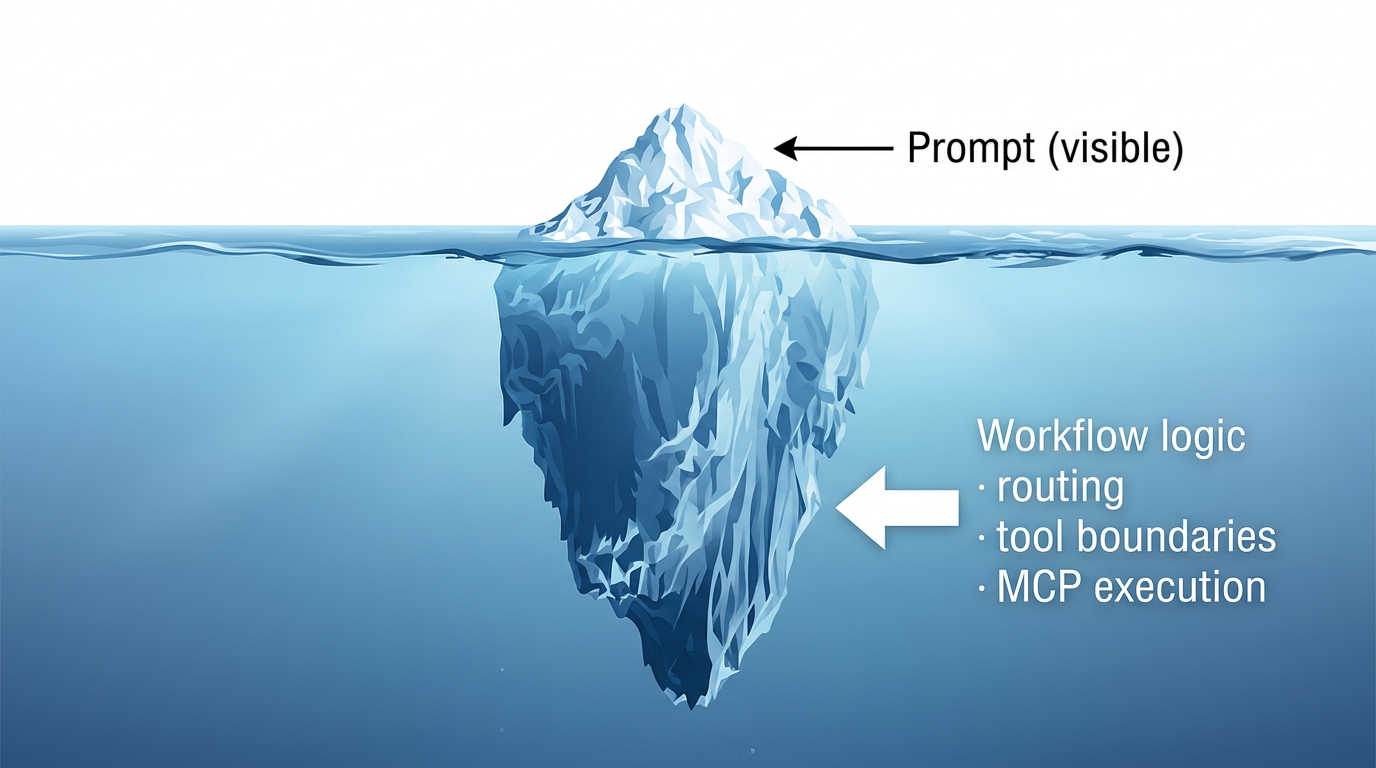 The prompt is the visible tip. Most operational behavior lives below the surface in workflow logic, routing assumptions, and tool-execution boundaries.
The prompt is the visible tip. Most operational behavior lives below the surface in workflow logic, routing assumptions, and tool-execution boundaries.
Core Architecture: Prompt, Skill, and MCP Are Different Layers
The cleanest way to describe the stack is this:
- The prompt says what the user wants.
- The skill constrains how the system should proceed.
- MCP provides a standard way to connect the model to external tools, data sources, and workflows.
The official MCP introduction describes MCP as an open standard for connecting AI applications to external systems such as data sources, tools, and workflows: What is the Model Context Protocol (MCP)?. That is transport and interoperability, not reasoning.
A skill does not replace the model. It wraps the model in procedural constraints and external execution paths.
That separation is the part many teams skip. They collapse three concerns into one bucket called “agent capability,” then act surprised when debugging becomes impossible.
| Layer | Actual Nature | Primary Job | Deterministic | Failure Pattern |
|---|---|---|---|---|
| Prompt | Text input | Express user intent and local context | No | Ambiguity, omission, prompt drift |
| Skill | Workflow definition | Shape reasoning order, routing, and checks | No | Wrong branch, hidden assumptions, brittle reuse |
| MCP | Protocol boundary | Connect the model to tools and data | Mostly yes | Permission errors, bad schemas, unsafe tool exposure |
The important point is that a skill does not magically upgrade the underlying model. It narrows the path the model is allowed to walk.
The Execution Loop: Where the Real Behavior Emerges
The model’s behavior is not stored in a single file called “skill.” It emerges during execution, one decision at a time.
This is why the statement “the model has the skill” is imprecise. What it really has is temporary access to:
- a workflow description,
- a tool schema surface,
- some local state,
- and a series of opportunities to make the wrong decision.
That last part is not cynicism. It is architecture. AgentBench is useful here because it evaluates LLMs as agents in interactive environments and highlights recurring failure modes such as poor long-term reasoning, weak decision-making, and instruction-following gaps: AgentBench: Evaluating LLMs as Agents.
So when a team says, “We added skills,” the next question should be: what new control loop did you add, and where can it break?
The Marketplace Problem: Volume Looks Like Capability
Large skill catalogs create an illusion of maturity. The number of entries grows fast, but volume is not the same thing as differentiated capability.
What usually happens in practice:
- many skills overlap in intent,
- naming is inconsistent,
- evaluation criteria are weak or nonexistent,
- and most entries encode a perspective on how to solve a task, not a verified guarantee that the task will be solved well.
 A marketplace can look rich while still being dominated by overlapping workflows and shallow differentiation.
A marketplace can look rich while still being dominated by overlapping workflows and shallow differentiation.
That does not make marketplaces useless. It makes them dangerous to interpret naively. They sell packaging, curation, and workflow opinions. Sometimes that is valuable. Sometimes it is just taxonomy theater.
The Nightmare Zone: Engineering Trade-offs Do Not Disappear
Production systems do not care whether the workflow was marketed as a skill, an agent, a recipe, or an automation pack. The system still has to pay the bill in latency, operational complexity, and blast radius.
The four recurring pain points are consistent across most serious deployments.
1. Selection Is Usually the First Failure
Once you accumulate enough skills, routing becomes the real system problem. The challenge is no longer “can the model do this task?” but “can the runtime select the correct workflow under partial context, ambiguous user intent, and noisy tool state?”
Wrong skill selection corrupts everything after it. The system can execute perfectly inside the wrong workflow and still deliver garbage.
2. Non-Determinism Never Went Away
A skill adds scaffolding. It does not remove the probabilistic behavior of the model sitting inside the loop.
You still have to account for:
- skipped instructions,
- partial tool misuse,
- hallucinated justifications,
- and silent failure when intermediate outputs look plausible enough to pass.
3. Latency and Cost Compound Step by Step
Every extra check, routing stage, tool call, or reflection pass adds cost.
At a simple level, the total latency can be reasoned about as:
$$ T_{total} \approx \sum_{i=1}^{n}(T_{reason,i} + T_{tool,i} + T_{validation,i}) $$
Where $n$ is the number of workflow stages. The equation is not sophisticated. It does not need to be. It is enough to remind teams that “just one more safety step” is never free.
4. Security Gets Worse the Moment Tools Become Real
The moment MCP or any equivalent layer can reach files, databases, internal APIs, or infrastructure controls, the attack surface expands.
Threat model questions that matter more than the hype cycle:
- What tools can mutate state?
- Where are the trust boundaries?
- What is the blast radius if the model selects the wrong action with valid credentials?
- Which operations require explicit human approval?
If those questions are not documented, the system is not production-ready. It is a demo with permissions.
Benchmark Reality: Generic Skills Rarely Travel Cleanly Into Production
One of the easiest mistakes is to confuse demo performance with production reliability. A generic pre-packaged skill can look competent in a narrow showcase and still collapse when it meets domain-specific edge cases, missing context, or enterprise governance constraints.
That does not mean skills fail by definition. It means the value comes from contextual fit, not from the label itself.
| Pattern | Best Use | Common Failure | Production Readiness |
|---|---|---|---|
| Prompt only | Simple, low-risk tasks | Inconsistent structure and no operational control | Low to medium |
| Generic marketplace skill | Fast experimentation | Hidden assumptions and weak domain fit | Low |
| Internal context-refined skill | Repetitive workflows with clear boundaries | Maintenance overhead and routing complexity | Medium to high |
The boring conclusion is the correct one: internal refinement beats generic packaging when the workflow actually matters.
The Architect’s Fork in the Road
If you are building serious agent systems, the decision is not whether skills are good or bad. The decision is what role you want them to play in your control plane.
Option A: Treat Skills as Reusable Internal SOPs
This works when:
- the workflow is repetitive,
- the permissions are bounded,
- and the quality bar can be measured.
This is the most credible use case. The skill becomes an internal operating procedure with versioning, evaluation, and auditability.
Option B: Treat Skills as Marketplace Commodities
This works only if you accept that you are buying someone else’s assumptions.
That may be acceptable for low-risk experimentation. It is a weak foundation for core business processes unless you re-verify the workflow, permissions, and outputs inside your own environment.
Option C: Treat Skills as a Human-Assist Layer
This is usually the safest pattern.
Let the skill draft, classify, route, summarize, or prepare. Keep final authority in human hands for actions that carry cost, compliance, or irreversible side effects. In practice, this is where many teams discover the highest ratio of value to operational pain.
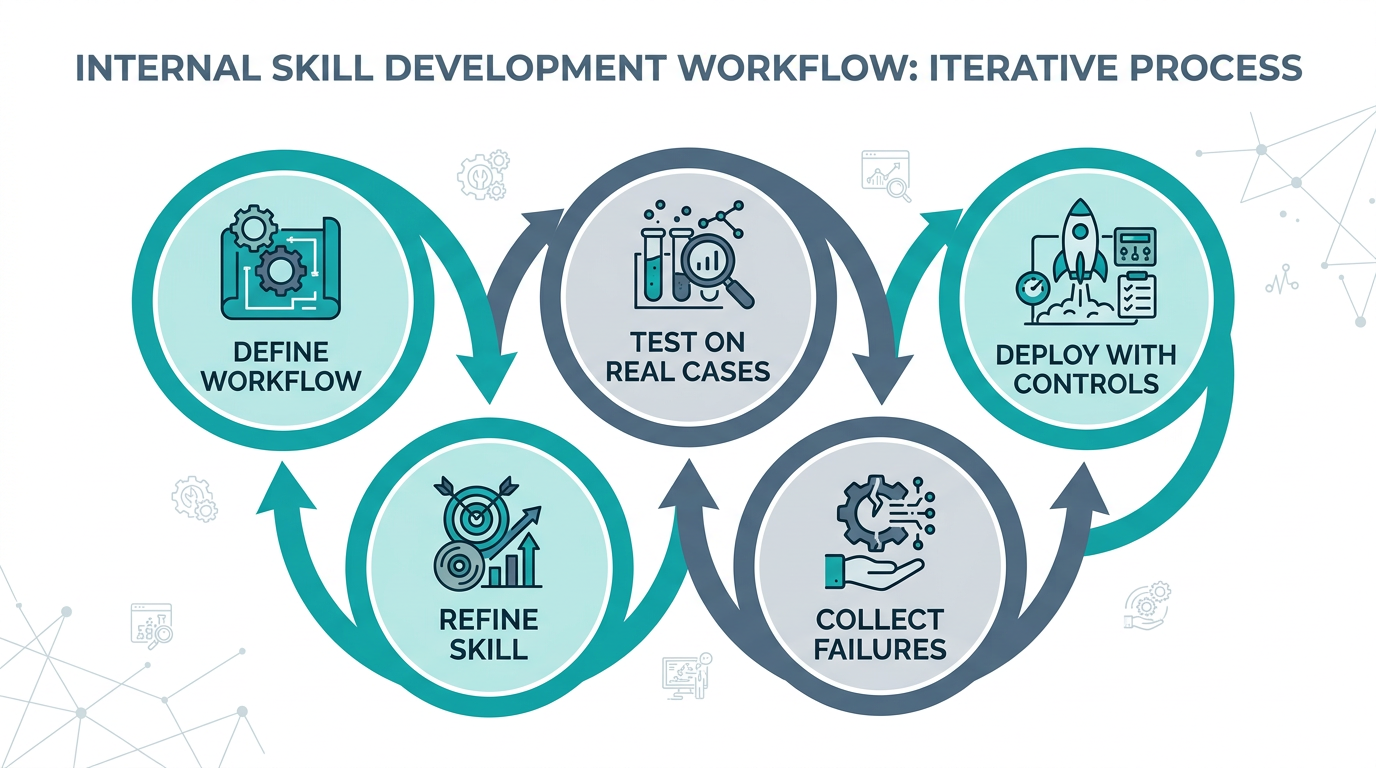 A workable internal loop is usually iterative: define workflow, test against real cases, deploy with controls, collect failures, and refine the skill rather than worship it.
A workable internal loop is usually iterative: define workflow, test against real cases, deploy with controls, collect failures, and refine the skill rather than worship it.
Final Thought
Skills do not replace thinking. They scale the consequences of whatever thinking is already embedded in the system.
If the underlying workflow is well-designed, the permissions are constrained, and the evaluation loop is honest, skills can improve consistency and reduce operator effort. If the architecture is weak, skills simply industrialize weak reasoning.
That is the real divide.
The teams that win here will not be the ones collecting the most pre-packaged skills. They will be the ones that understand their own workflows deeply enough to design, test, and constrain them like any other critical subsystem.